



大幅革新 AMD下一代图形产品前瞻
很快,Radeon HD 6000的时代就将过去,因为AMD下一代图形产品即将到来。请注意,这次不是如Radeon HD 6000和Radeon HD 5000一般,在上一代架构基础上小修小补。我们能明显发现新产品的设计理念,在向并行计算的方向靠拢。

本刊在8月上《打左灯,向右转? AMD Radeon HD 6000时代产品发展策略分析》一文中曾明确指出,AMD目前的图形产品的架构设计已经遇到了瓶颈,不适应风生水起的GPU并行计算。而AMD也充分意识到了这个问题,6月16日在美国华盛顿州Bellevue举行的首届AMD Fusion开发者高峰会上,AMD就向我们透露了下一代图形核心的有关情况(AMD Graphics Core Next,简称GCN)。GCN是AMD未来GPU的基石,包括传统的独立显卡,和APU集成的GPU核心。借助GCN,AMD将对沿用多年的GPU架构进行一次大变革,以满足GPU并行计算的要求。
GCN的设计指导思想是让GPU的并行计算性能和图形处理性能一样出色。采用VLIW设计的传统AMD图形产品并不太适合进行并行计算, AMD有必要和老旧的GPU架构划清界限,构建性能更好的GPU产品,以满足软件开发者需求。由于GCN的许多设计思路和Fermi类似,因此有人评论:“GCN本质上就是AMD版费米,全新架构加上大刀阔斧地改革,打造出怪兽级的并行计算和图形渲染性能!”
能温故而知新 AMD现有架构回顾
在了解GCN之前,我们先来简单回顾下AMD现有图形产品的架构设计。与NVIDIA图形产品采用MIMID(多指令多数据流)不同的是,AMD采用的是SIMD(单指令多数据流)架构。AMD图形芯片的基本单位是流处理算术逻辑单元,简称SPU。除了采用Cayman核心的Radeon HD 6900系列以外(采用VLIW4设计,每4个SPU组成一个SP),AMD一直以来都沿用的是“超长指令字5”设计,即VLIW5,5个SPU组成一个SP(流处理器单元)。这种设计的主要特点是以并行方式,在尽可能多的时钟周期内,执行单独指令。由于它可以比较容易进行编译和安排着色,因此擅长图形处理。SPU加上寄存器,一个分支单元,以及一个特殊功能(超越指令)单元,即构建成为1个SP。以采用传统VLIW5设计的Radeon HD 6850来说,每80个SP构成1组SIMD引擎,每7组SIMD引擎构成一个SIMD引擎阵列,Radeon HD 6850的Barts核心共计两个SIMD引擎阵列。
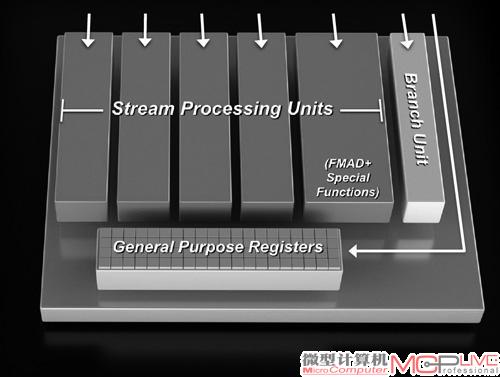
AMD的VLIW5设计示意图
采用VLIW设计的AMD显卡擅长把相同的任务分解成更小的分组,以并行方式执行许多操作,这种更小的分组即所谓的“波前“(Wavef ront)。就AMD来说,波前是64个像素/或者数值,以及相对应的执行指令列表构成的组。理想情况下,1个波前有4或5个完全独立的指令。当遇到互相依存的指令时,1个波前将包含更少的完全独立指令;坏的情况下,一个SP(包含4个或者5个SPU)在1个时钟周期内只能处理1个指令,有3个或者4个SPU完全闲置。

传统VLIW设计的指令执行示意图
随着DirectX 11游戏和GPGPU方案问世,根据AMD自己的内部研究显示,在Cayman发布之时,采用VLIW5设计的AMD显卡在当下的应用环境下,平均只利用到5个SPU核心当中的3~4个。从VLIW5收缩到VLIW4,就是为了应对这种变化,不过SPU核心的利用率始终是个问题。

GCN中的SIMD向量处理器结构图
后,不得不说的是安排这些操作的调度单元。在CPU的世界里,我们让CPU执行程序,CPU自己会进行必要的调度安排,甚至可以在一个线程当中进行乱序执行。而在VLIW设计当中,编译器负责一切调度工作。编译器需要了解全部程序,并智能地预先安排一些操作。但同时它也有无法预知的地方,必须等程序运行之后并且提供数据给自己才行。因此,编译器在VLIW设计当中是所谓“静态”运行,它在编译之前就设定一切,并且编译过程当中不能发生变化。而且每一个编译器都要非常出色才行,不然在支持扩大语言的时候就会遇到问题,甚至在中间语言抽取过程当中都会遇到问题,比如着色编译器无法处理某个编译器产生的中间代码等。
此外,VLIW指令集的复杂性也会妨碍程序优化和手工优化调整,这在进行并行计算时都容易遇到问题。VLIW的复杂性使得它难以拆卸和调试,很难预测性能,并发现和修复代码的关键部分。理想情况下,程序员不应该使用汇编进行工作,但高性能计算和其他并行计算的用途却恰恰相反,通过汇编工作,同时对单指令进行优化,可以获得更高性能。

